Continual Learning for LLMs - without update regressions.
Our continual learning solution is a physics-inspired approach designed to reduce catastrophic forgetting and stabilise sequential updates. Use it across continual pretraining, instruction tuning, alignment and safety refreshes, and domain adaptation so your model can keep learning while retaining prior capabilities.
Why LLM updates break: catastrophic forgetting
LLMs are updated continuously for policy changes, domain refreshes, new products, and evolving support workflows. Sequential updates can degrade old capabilities and cause regressions, turning model updates into a business risk: more support tickets, quality regressions, compliance drift, and re-validation costs.
Different models forget differently, but the bottleneck persists
Different architectures and tuning recipes shift what fails first: instruction following, safety behaviours, or domain skills. Continual learning for LLMs is multi-stage, and cross-stage iteration can compound forgetting over time.
Dataset size, diversity, and domain narrowness influence severity, but they do not eliminate interference. Catastrophic forgetting returns across pretraining refreshes, instruction tuning waves, and alignment updates, making it a persistent operational bottleneck.
What you can control: reduce destructive interference
Continual learning offers practical tools: constraint-based methods, replay or memory, and architectural strategies. Nabu prioritises a solution-first approach for enterprise feasibility: lower memory overhead, simpler integration, and a predictable cost profile. This approach draws from established continual learning research, including constraint-based methods such as EWC and comparisons with replay-based techniques such as GEM.
Our continual learning solution: physics-inspired stability across updates
Our continual learning solution is a physics-inspired approach designed to reduce forgetting and stabilise sequential updates. It is model- agnostic and workflow-agnostic, and it integrates through an API key and endpoint so you can use it wherever you update models. Private preview: the API is not yet operational.
- Helps retain prior capabilities across sequential updates
- Reduces update regressions
- Improves stability and rollout confidence
- Supports lifecycle-wide training stages
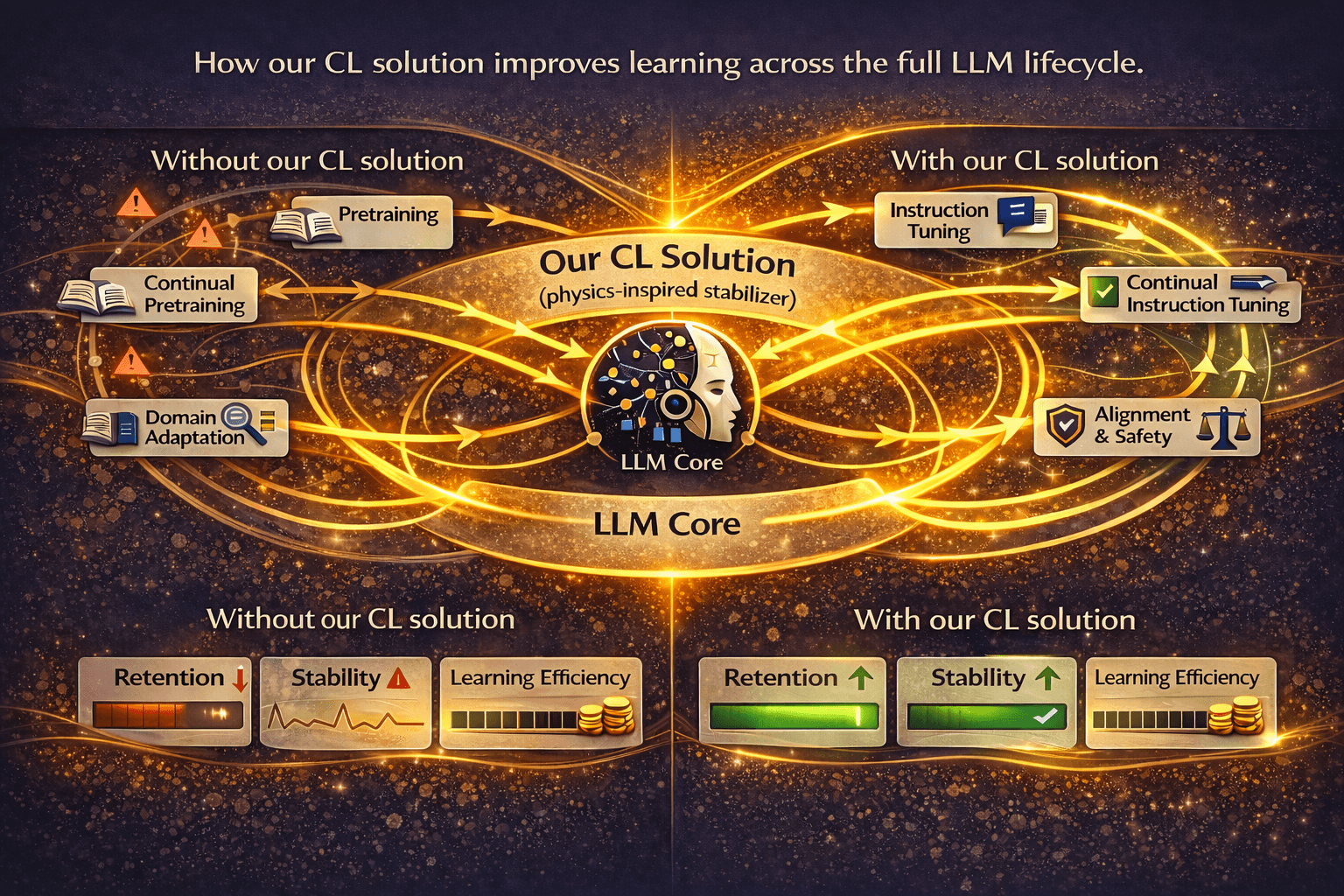
One platform across the full LLM lifecycle
Continual learning in LLMs is multi-stage: continual pretraining, instruction tuning, and alignment. Forgetting can accumulate across stages, not just within a single fine-tune. Our solution is positioned as a lifecycle-wide platform, usable wherever sequential updates occur.
If you update LLMs, our solution is for you
Ideal customers
- Teams shipping LLM features with frequent updates
- ML platform teams maintaining internal assistants
- Fine-tuning vendors and consultancies delivering repeated client adaptations
- Enterprises running compliance, policy, and safety refresh cycles
Benefits
- More stable update cycles (fewer regressions)
- Better retention of prior behaviours
- Lower pressure to retrain from scratch
- Standardised integration across lifecycle stages
Built for production constraints
Designed for teams that need reliable updates without exposing model internals or taking on replay infrastructure.
- Privacy-first integration with minimal required metadata
- API key access control and usage quotas (preview configuration)
- Enterprise options: SLA and support, private connectivity available
- Private preview access for early adopters
Privacy by design: loss-only computation
Our API is designed to compute an improved form of training loss during your run, nothing more. We do not cache or store your prompts, batches, gradients, model weights, checkpoints, or datasets. Requests are transmitted encrypted in transit, processed to produce a loss or penalty signal and summary metrics, and returned encrypted. We do not need to know what model you run, where you run it, or what your data contains. From our perspective, your training job remains opaque: you receive a better loss signal and metrics; we learn nothing about your run. If any operational logs are stored, they are encrypted at rest.